

Does your organization struggle with data sprawl? Do you have valuable information scattered across a myriad of different silos, tools, and personal computers? Are you dealing with duplicates or inconsistently named datasets that complicate the data management process? Or perhaps, your dilemma is having numerous different datasets with the same name — or what appear to be copies of the same dataset but with different names — leading to confusion and inefficiency?
Matterbeam's Search addresses these challenges by helping you streamline your data search and discovery process. As you type, Matterbeam will search across the names of datasets, domains, teams, transforms, and emitters, as well as the domains and descriptions of all of these components and their subcomponents.
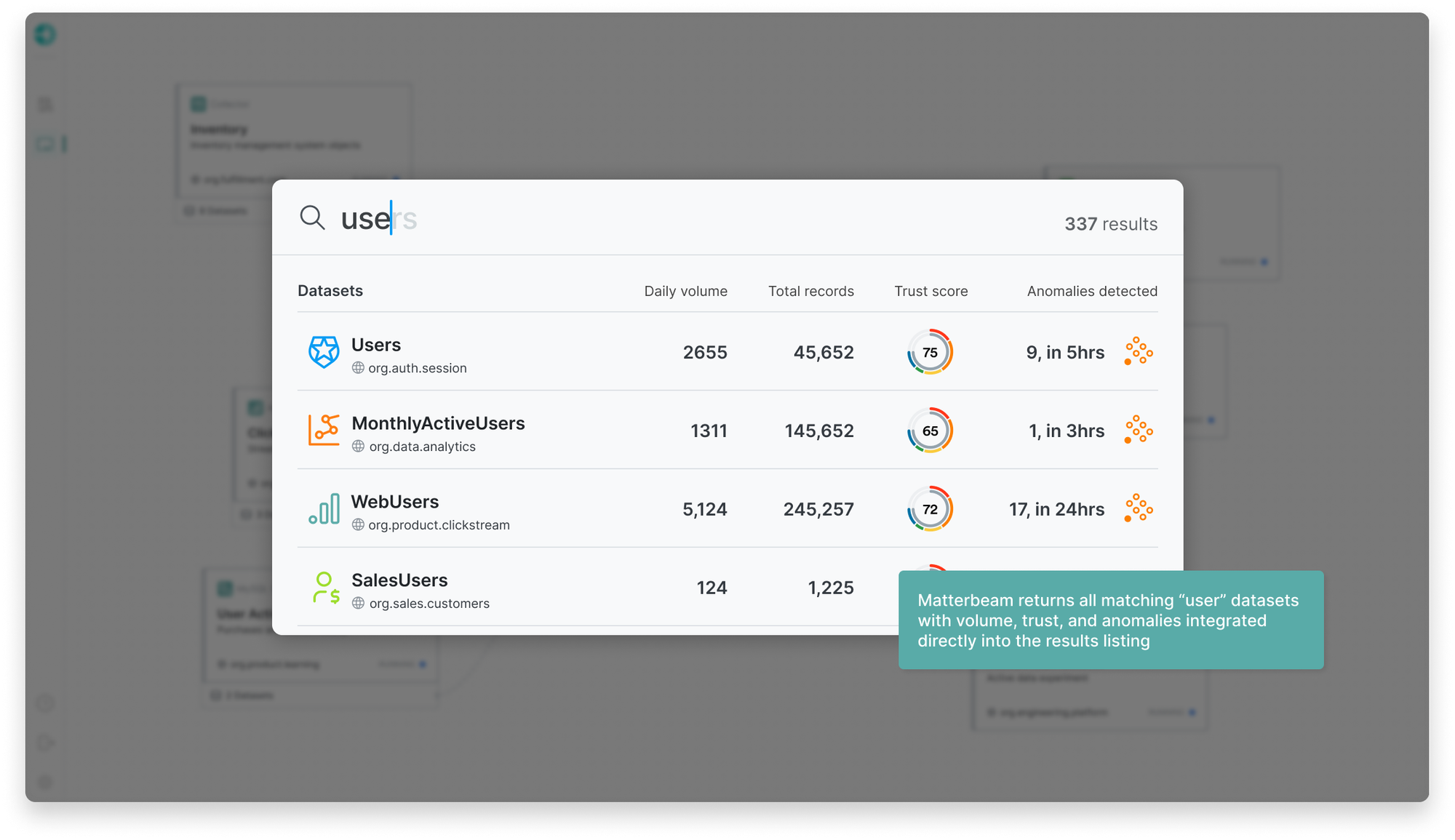
If you aren't sure which result to choose, the Matterbeam Trust Score will give you deeper insight and confidence to help you determine which datasets you can use or take dependencies on. The Trust Score calculates a score based off five factors.
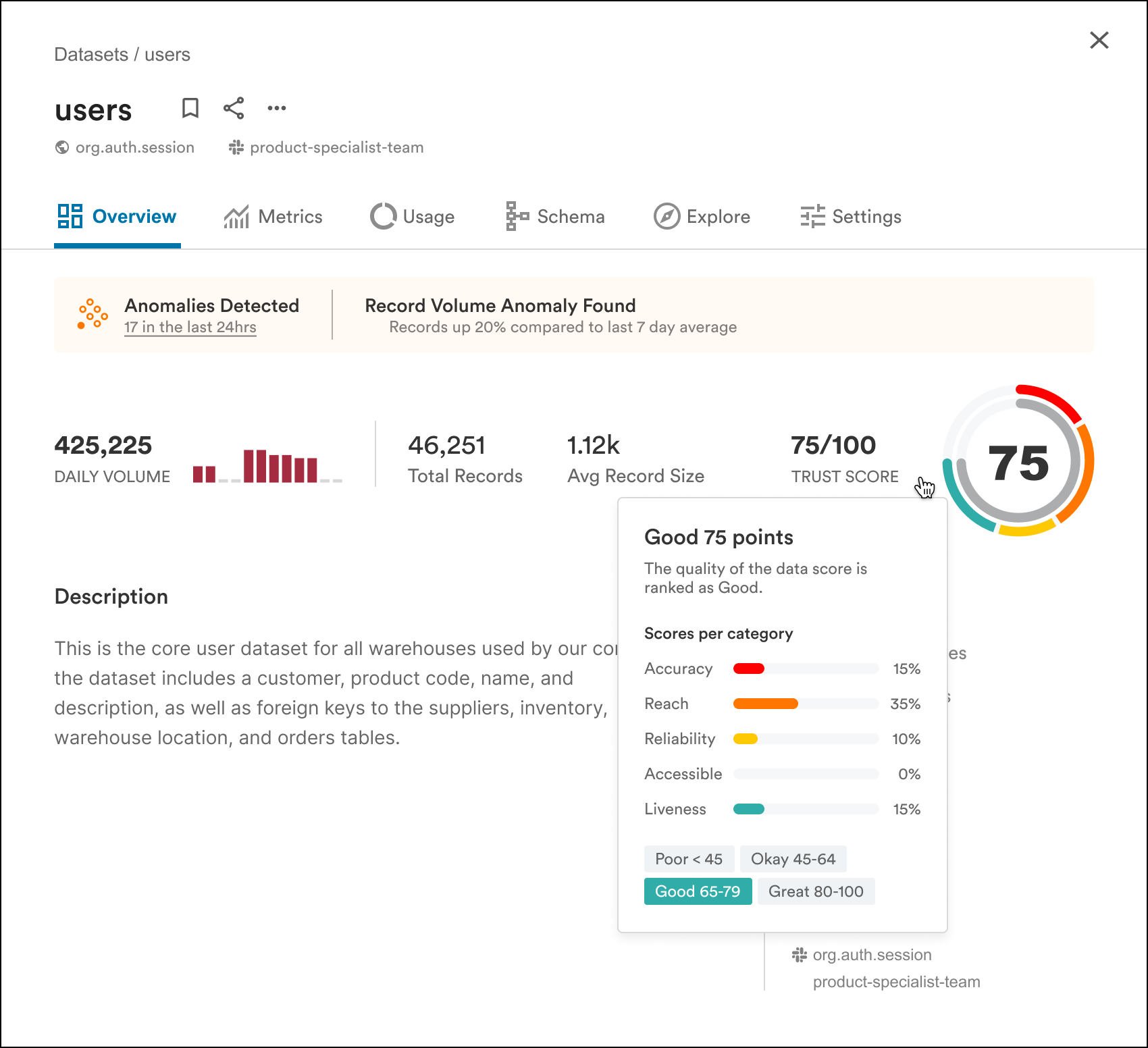
In addition to the Trust Score, Matterbeam performs Anomaly Detection for all datasets. In the background, Matterbeam identifies unexpected patterns or outliers in datasets that deviate from the norm, which can indicate errors, confusion, or significant changes.
By using statistical and machine learning techniques, Anomaly Detection helps prevent downstream impact, maintain data quality and integrity, and ensuring accurate analysis and decision-making. If any anomalies are detected, like unusual record volume, then Matterbeam will highlight that on the dataset and provide the option to dig deeper.
If you're interested in testing or deploying Matterbeam for a particular data challenge we'd love to talk.




