

Data integration tools are notoriously complex, and most organizations already have a substantial amount, so you're probably wondering...
How long will it take to introduce this into my data stack and data operations workflows?
TLDR - not long at all. Here’s why...
Matterbeam is a Data Agility Platform built on AWS, leveraging an event-driven serverless architecture that eliminates the need for you to do any complex setup. To start, simply login in using your browser with SSO or Google.

Choose from our list of pre-built data collectors to bulk load or stream data in. For example, the S3 Collector retrieves data directly from S3. You don’t need to know the details of the use case or how the data will be used downstream in order to collect data.
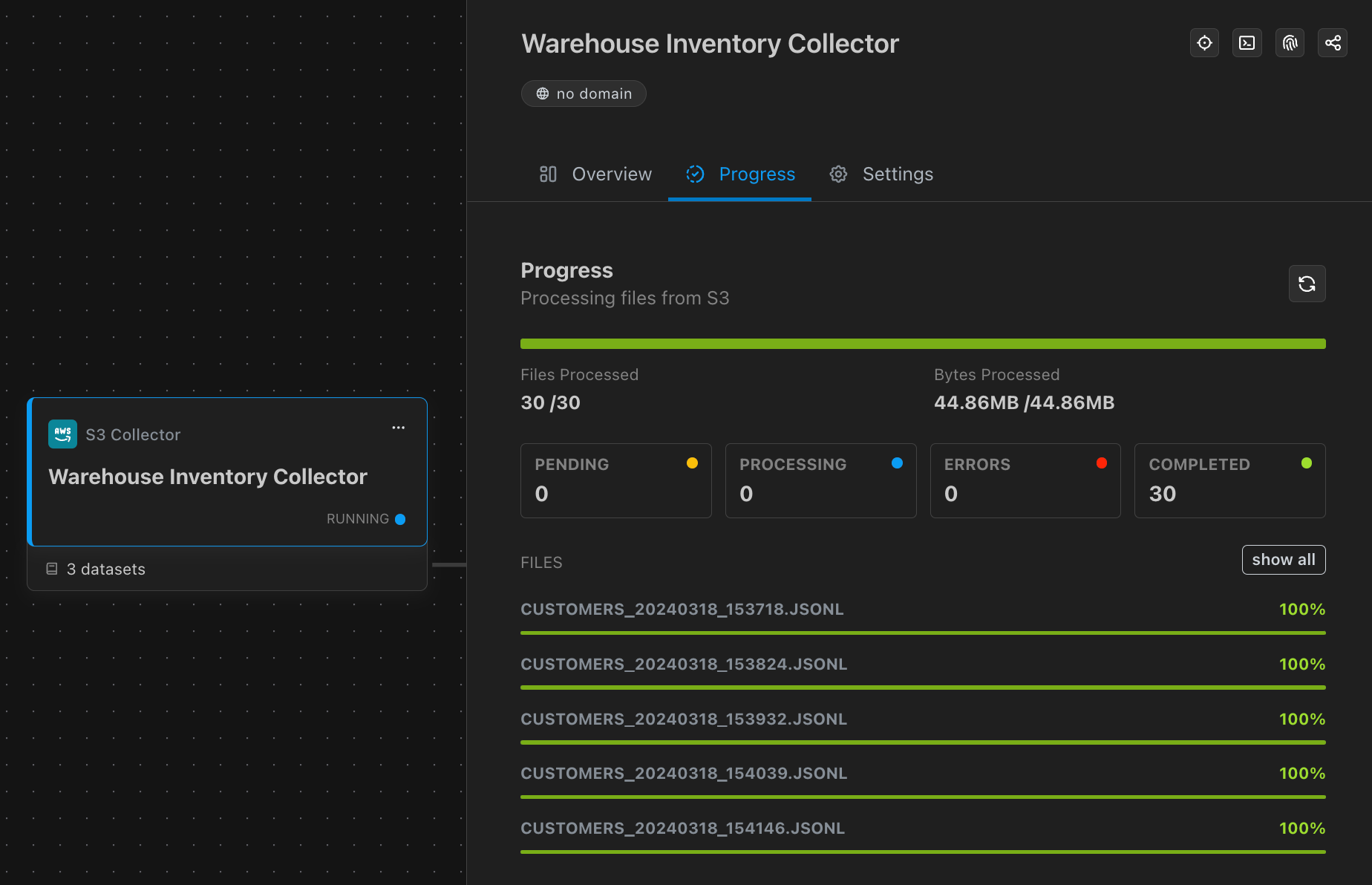
...but for those who want them, more customized options are available too - like posting data to our HTTP collector.
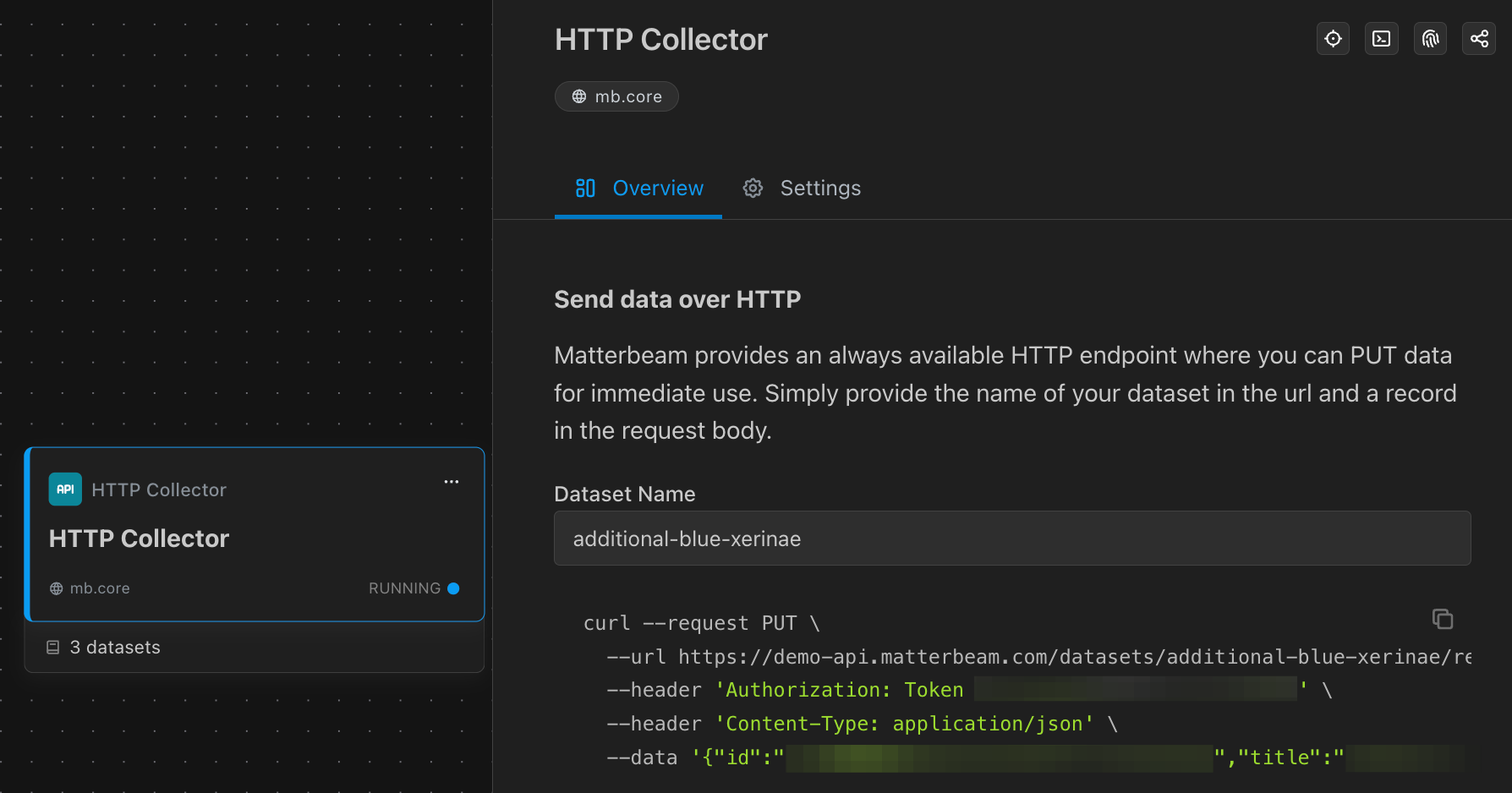
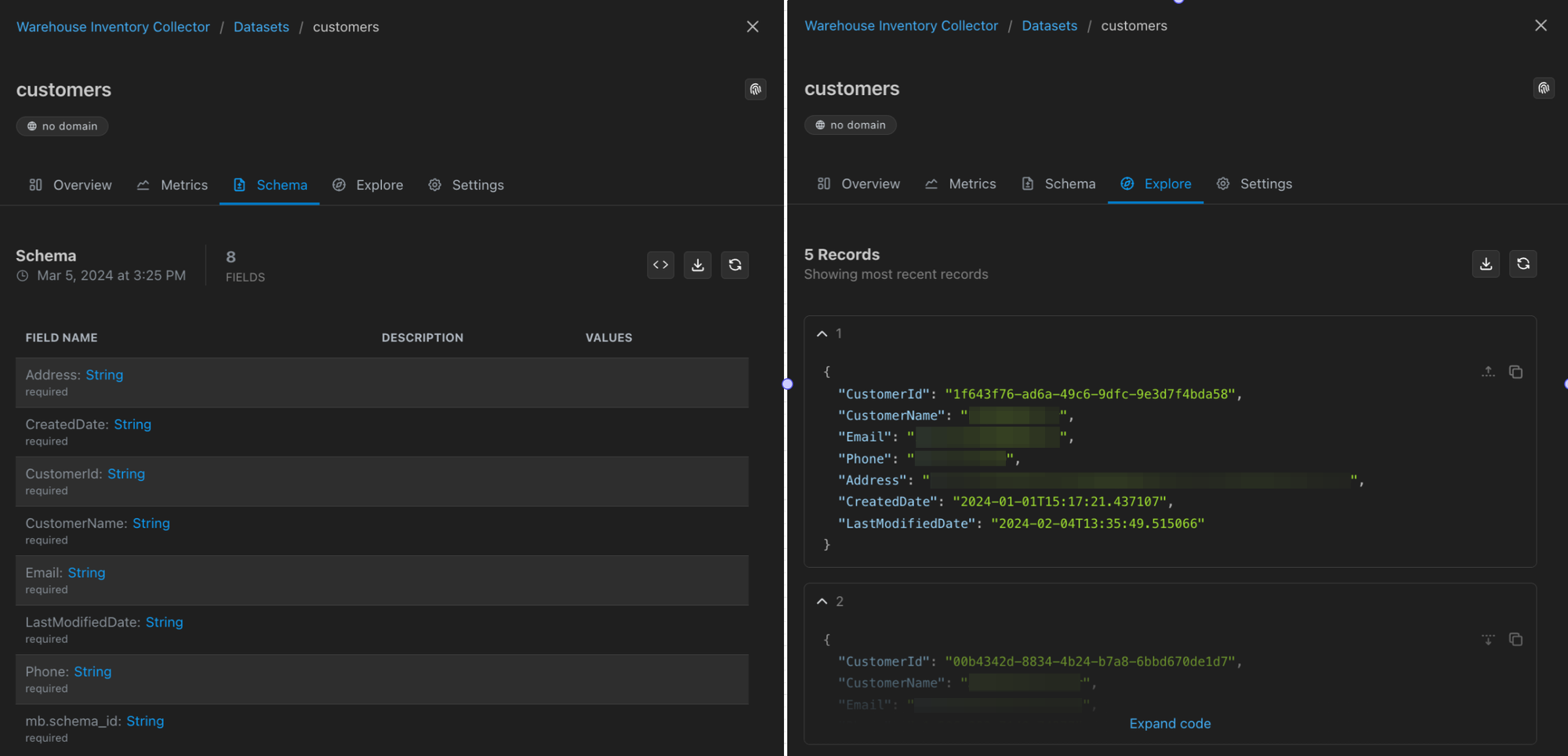
Matterbeam detects and learns your data's schema automatically and stores your data in our common record format. You can Explore the schema or preview records from your data right after your start collecting.
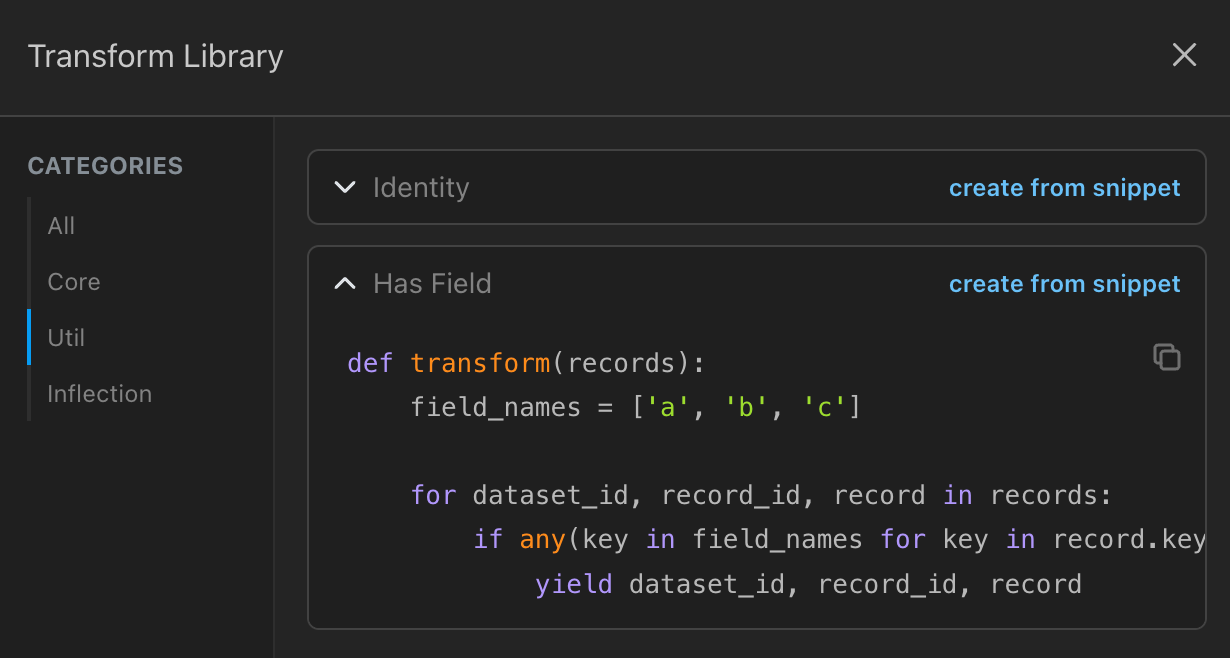
Easily join or filter your data by running your dataset through a transform using a python transform template. We support Stream Joins (aka stateful transformations) and custom user-defined python transforms. The same dataset can be transformed and used for endless use cases without disrupting upstream data flows.
It's free to emit live datasets out of Matterbeam. Select from our list of Emitters, like MySQL, fill in your connection and config details, and that's it. We make sure the data is sent to your destination correctly and abstract away much of the complexity of data formatting.
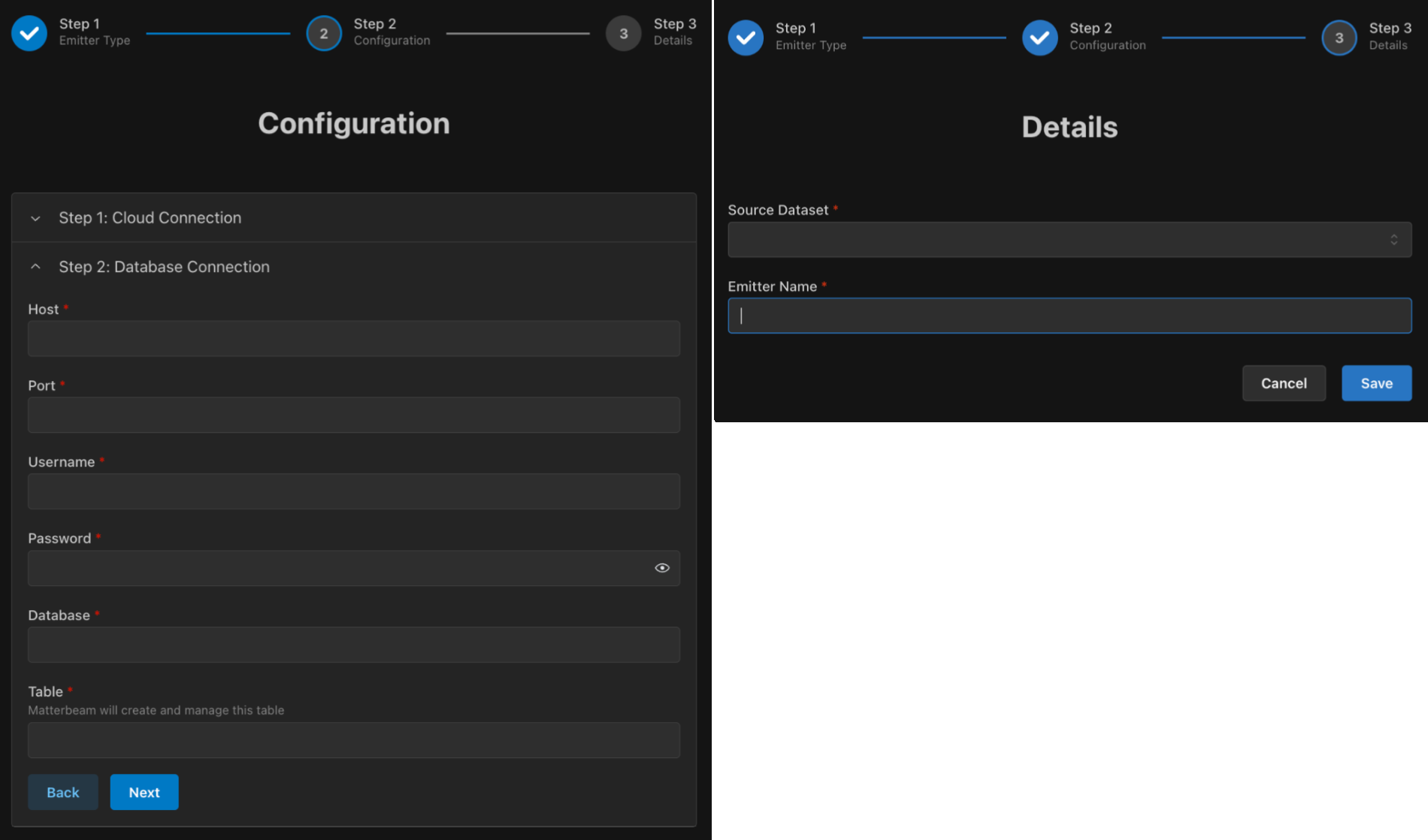
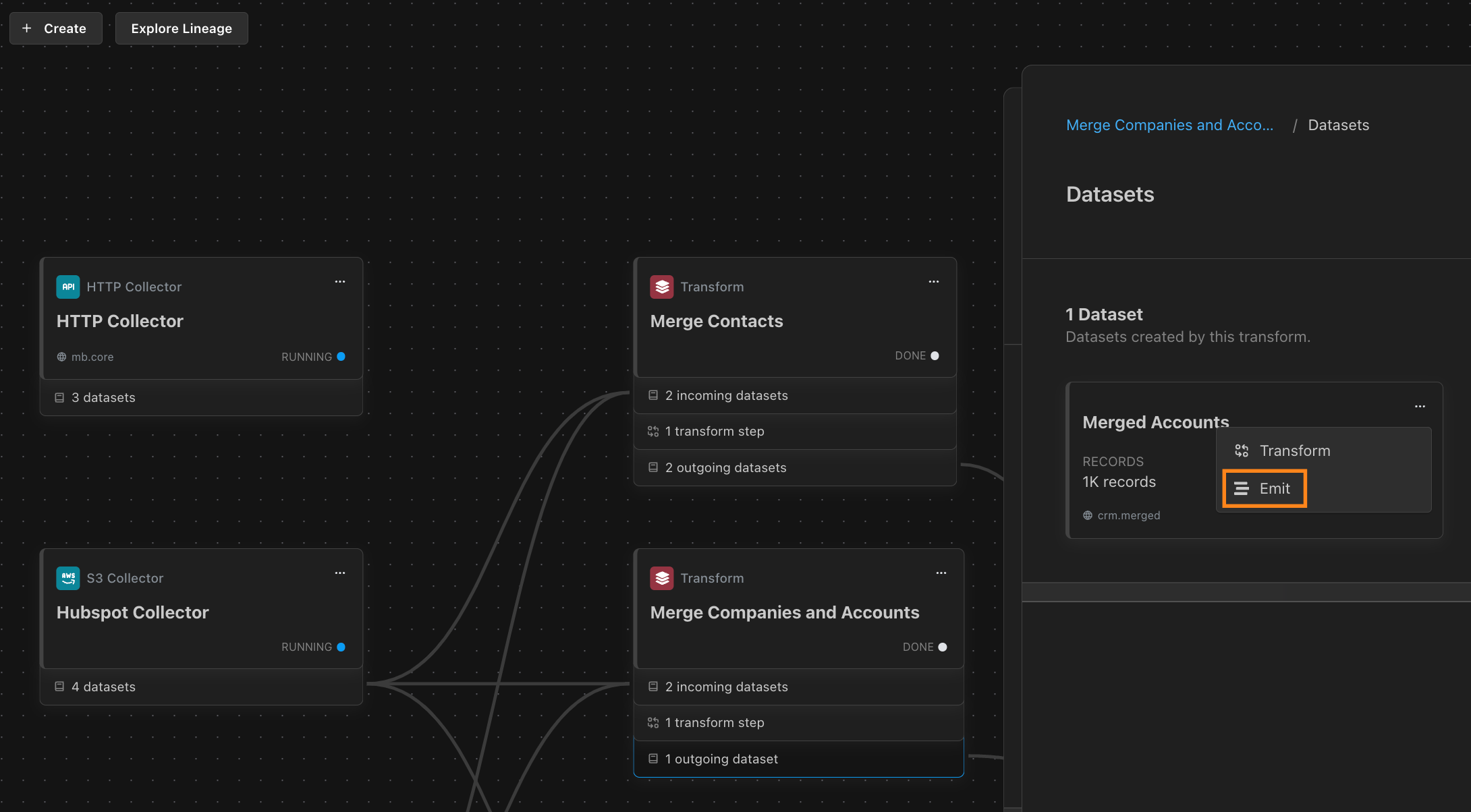
Matterbeam datasets can be streamed or replayed to multiple target systems without having to rebuild the upstream part of the data flow and without taxing your source system. Choose any dataset from anywhere in your existing Matterbeam data flow landscape, emit with Replay enabled, and this will include any historic data you need. Replay lets you choose a start date to ensure your new target system is up to date. (The Replay will be billed but any data emitted live after that is free.)

Next time your colleagues ask you for that data, just point them to Matterbeam. They can fork off a dataset you already transformed and emit that to their target system of choice. Alternatively, they can fork off your source-aligned dataset and make their own transform directly in Matterbeam if they have a custom request and want to get crafty before emitting the data to their destination.
Whether it's the person who asked for your data, or it's you looking for another department's data, sometimes it's hard to know what you need. We might not know where to look, what dataset to use, or even who to ask.
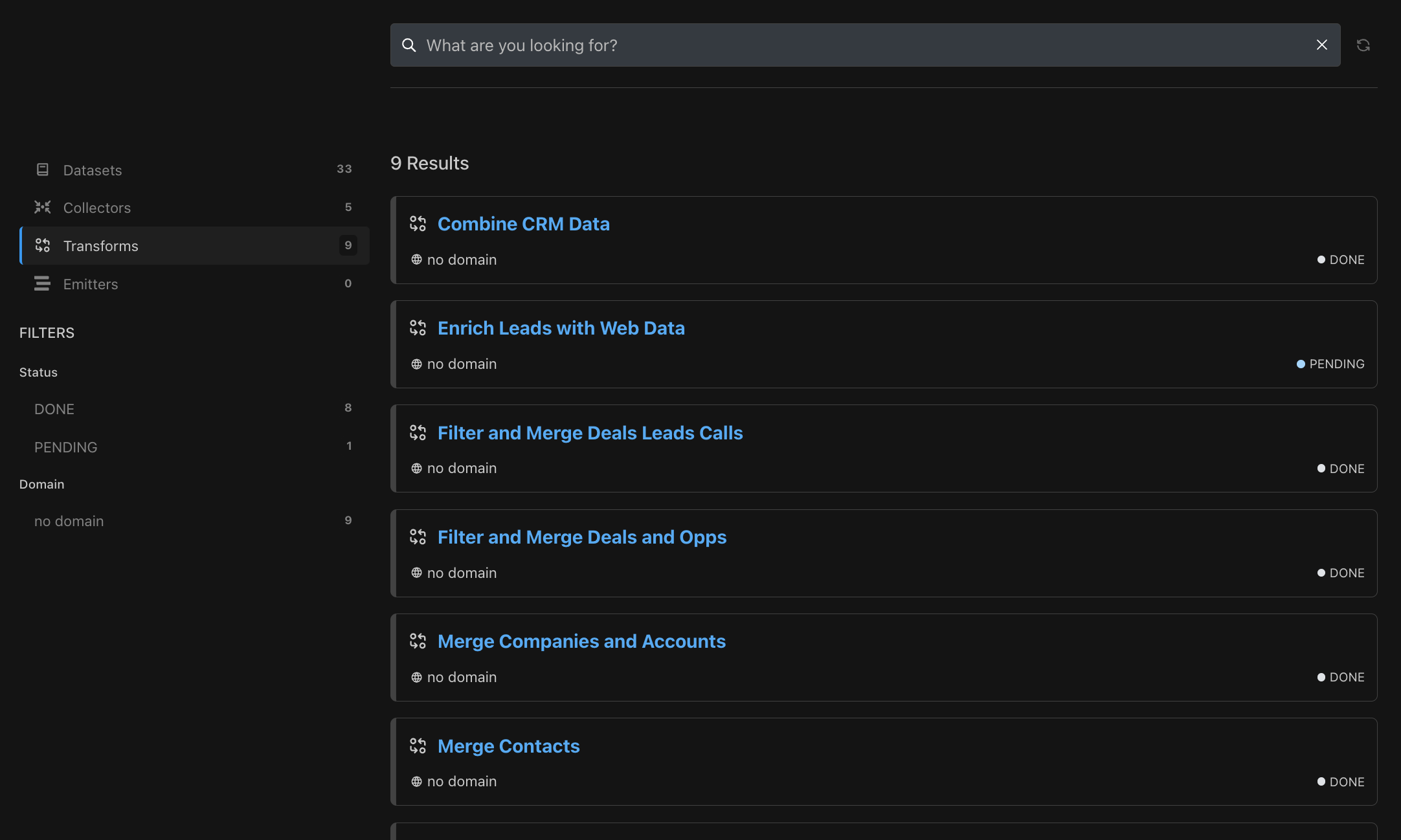
Our Studio data landscape view and Data Lineage view help you get started with the thousand foot view. Click to highlight paths or dive deeper into each dataset by looking at its Trust Score, domain, or owner.

When you know what you're looking for, our advanced search in the Catalog includes filters to help you find it faster.
No one likes confusing, opaque, and complicated pricing. We keep it simple and charge a flat rate to stream, replay, and transform, measured by GB, per month.
If you're interested in testing or deploying Matterbeam for a particular data challenge we'd love to talk. Email us or:




